
Naveen Raman
PhD Student Carnegie Mellon University
Previous MPhil @ University of Cambridge, Undergrad University of Maryland
naveenr [AT] cmu.edu
The Marginal Value of Language Model Capabilities
Language Models and Productivity
We have a reasonably good understanding of the factors that impact language model capabilities (e.g., dataset and model size), yet our understanding of how this translates to usefulness in practice lags behind. That is, we lack estimates of the marginal value of language model capabilities, where we use marginal value to capture how improvements in capabilities translate into real-world impact. While calculating this quantity requires concerted effort from both researchers and practitioners, it informs us about when further investment in capabilities is worthwhile, how different tasks evolve as models progress, and which tasks benefit the most from human expertise. Importantly, this relationship is also shaped by human and organizational factors beyond model capabilities.
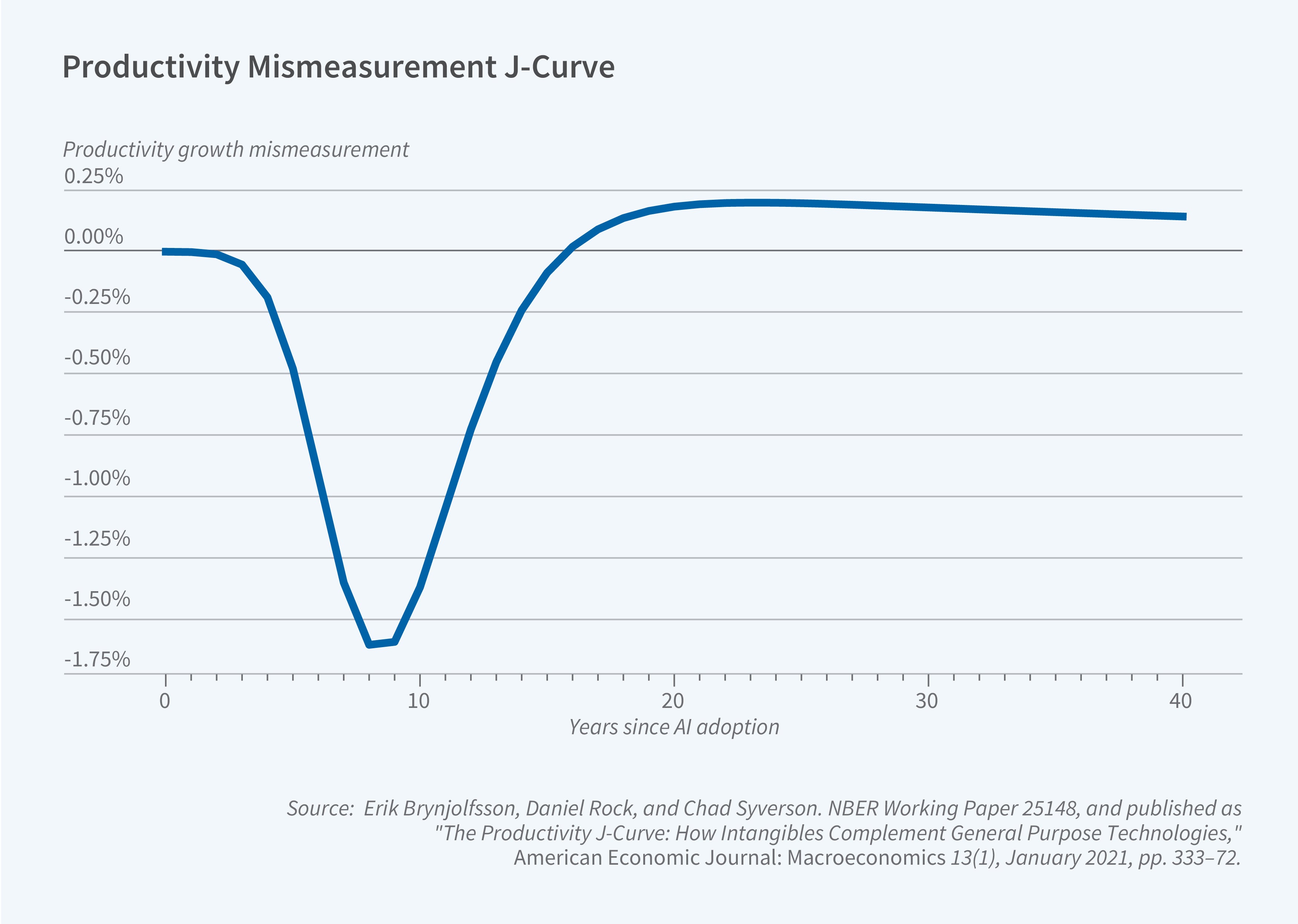
Source: Brynjolfsson et al.
Economists provide at least a partial picture of what this relationship might look like. Work by Erik Brynjolfsson and collaborators shows that productivity gains from new technologies such as AI follow a J-curve, where productivity first dips then increases over time. The initial dip corresponds to adjustments made by workers to better align and understand the technology, while the later rise and plateau correspond to workers acclimating and integrating the technology for day-to-day use. Similar curves have also been used to understand the historical impact of software adoption and other general-purpose technologies.
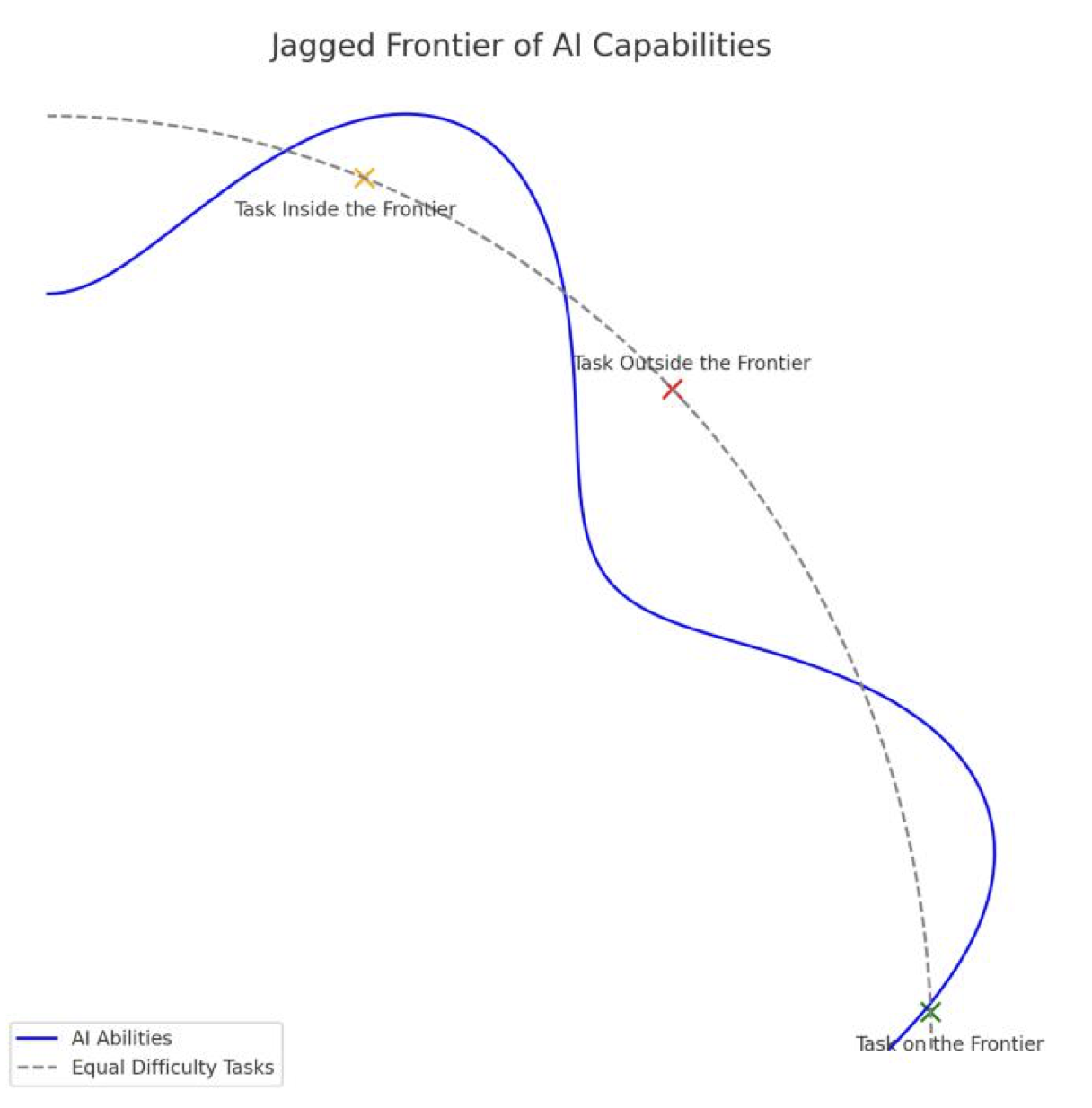
Source: Dell'Acqua et al.
While aggregate productivity follows a smooth curve, task-level curves vary significantly. The impact of AI is jagged because AI competencies don't necessarily correspond to human judgments of difficulty. For example, memorization tasks are hard for humans and easy for AI, while spatial reasoning is easy for humans and harder for AI. As AI progresses, this frontier expands, with AI improving across tasks and finding new capabilities. However, such improvements are not necessarily uniform; certain trivial tasks might take years until AI gains superhuman performance, while others might improve quickly. These per-task differences remain poorly understood and are a key reason to study the marginal value of capability improvements.
Measuring the Marginal Value of Capability
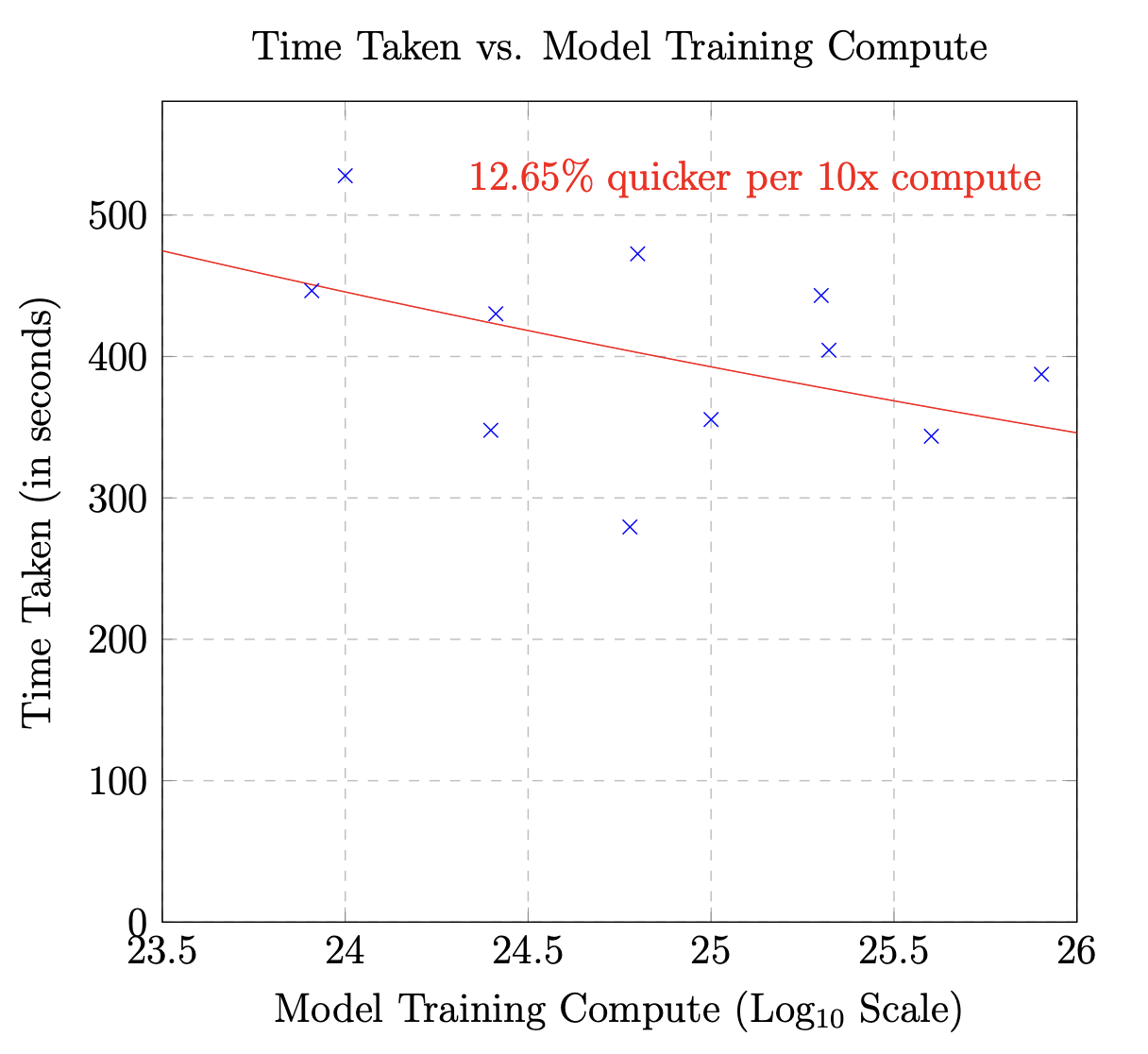
Source: Merali
Understanding how task performance scales with model capability allows us to estimate what the real-world impact of AI might be, and naturally connects to the broader literature on scaling laws. Yet unlike traditional scaling laws, defining what should be on the X and Y axis for such a curve is difficult. On the X axis, a natural quantity is test loss. However, models with similar test losses could be fine-tuned on different datasets, bringing up the question of whether we should measure task-specific performance. Another alternative is to measure properties of a model, such as the amount of training compute or model size. The argument here is that these quantities naturally correspond to capabilities and are easy-to-measure. For example, the translation study discussed below uses training compute as a proxy for capability. This treats differences in post-training or fine-tuning as secondary and asks how downstream usefulness scales with overall model scale.
The Y axis requires quantifying task performance, but is difficult to define correctly because of inter- and intra-task variation. Different tasks have different measures of performance, and many tasks are complementary or are hard to measure (if measurable at all). Moreover, even if we can quantify task-specific performance, there are other mitigating factors present. As an example, if the task depends on the amount of time needed to complete the task, then we could either fix the time and measure quality, or fix the quality and measure the time. Additionally, confounding variables such as experience with AI and subject-matter expertise could create substantial uncertainty.
While this broader research agenda is still underdeveloped, early case studies provide hints about what these curves might look like. For example, recent work examined how improvements in language models affect translator performance. The study compared translator performance when interacting with 13 language models that varied in capability. The key finding is that increases in training compute lead to noisy but roughly monotonic improvements in both the time taken and translation quality. Critically, few papers evaluate real-world impact across models of varying capability, and we need more such work.
Questions and Conjectures
Generating marginal capability curves allows us to answer a series of questions; each question looks at what role human factors play in addition to AI capability, and how this changes as AI becomes more capable.
Question #1: Do all tasks share the same general curve for capability vs. performance?Details: Generating capability curves allows us to perform inter-task comparisons to identify which tasks respond quickest to model improvements. A natural conjecture is that all tasks follow a roughly sigmoidal shape, with the location of the inflection point being task-dependent. This would match progress on some benchmarks, where there's a natural floor and ceiling to performance. However, the existence of baselines and eventual plateaus does not guarantee a sigmoidal distribution. Instead, one alternative is the presence of several inflection points where performance increases dramatically, which can lead to complex curves depending on the task structure. As an example, in coding, a certain level of model capability allows models to independently write modular functions. A more capable model allows us to go beyond writing functions to writing entire applications with it, creating a sharp discontinuity, not because the model is sharply better (or even because the phenomenon we measure is sharply better), but because the way we use models is discontinuous at certain points. Then, as a model developer or practitioner, the goal is to get the performance in a particular domain just beyond the last of these inflection points, if such inflection points exist.
Conjecture: Most tasks will follow a sigmoid-like curve, but tasks that are more "complex" (or require composition or orchestration of smaller parts) will exhibit multiple inflection points. This is not necessarily the same as the tasks which are hardest for humans.
Question #2: Which is the bigger inhibitor of real-world impact: model capabilities or model integration?
Details: Our ability to generate value from language models requires not only strong models, but also the knowledge of how to use such models effectively in practice. On a capability graph, this might be seen as large amounts of variation between users; some organizations have an easier time integrating the tool into existing workflows, while others see little benefit from model improvement. For example, in healthcare, we not only need models that are able to perform diagnoses quickly and accurately, but also ways that the models can be easily integrated into clinical and regulatory workflows, while also being trusted by doctors. Broadly, we could see two regimes: those where we have sufficient model capability, but not enough model integration, and others where model integration is the key bottleneck. Here, integration can capture all non-capability elements, including whether users know how to use the model, when to trust it, etc. Natural implications for tasks which are integration-bottlenecked are to develop better interfaces and pipelines.
Conjecture: For many tasks, factors beyond model quality are the limiting factor; how the model is being used will matter more than model quality for a growing number of tasks.
Question #3: Does inter-user variation for a fixed task increase or decrease with better models?
Details: Several factors can account for variation between users including differences in experience with AI, differences in expertise, and different setups for the use of AI. Understanding inter-user variation allows us to see whether people's performance converges with better models and how experts and non-experts change with increasing model capability. One possibility is that increases in AI capabilities democratize expertise, which leads to less variation and increased homogeneity in performance. The other possibility is that domain expertise complements language models in ways that non-experts cannot easily replicate. Here, language models serve as a force multiplier that accelerates performance when combined with expertise. We note that expertise can be subdivided into multiple aspects, including expertise related to AI and expertise in a particular domain.
Conjecture: Individual-level heterogeneity will dominate, especially as models become more competent. Expertise will be maintained even as models improve because the main inhibitor is skill in using language models, and experts are better at evaluating LLM output.
We still have some ways to go to be able to answer these questions, as we still need to figure out what the right metric is for different tasks and to collect data that estimates real-world performance. Studies such as the one involving translation show that this is tractable, but we just need to scale this up across a wider task distribution.